Introduction
Utilizing machine learning in healthcare and accompanying medical devices has the potential to greatly improve clinical care outcomes for patients. As more AI-enabled medical devices continue to get approved (see FDA approved devices), it’s important to adhere to a set of design guidelines and best practices when developing your AI-enabled medical device.
As the FDA and associated agencies continue to work on developing formal guidelines for AI-enabled medical devices, they recently put out a document entitled Good Machine Learning Practice for Medical Device Development: Guiding Principles. I thought this document provided a good outline of best practices to be used in any machine learning project dealing with medical predictions.
Below follows my comments on the principles outlined in the document:
1. Multi-Disciplinary Expertise Is Leveraged Throughout the Total Product Life Cycle
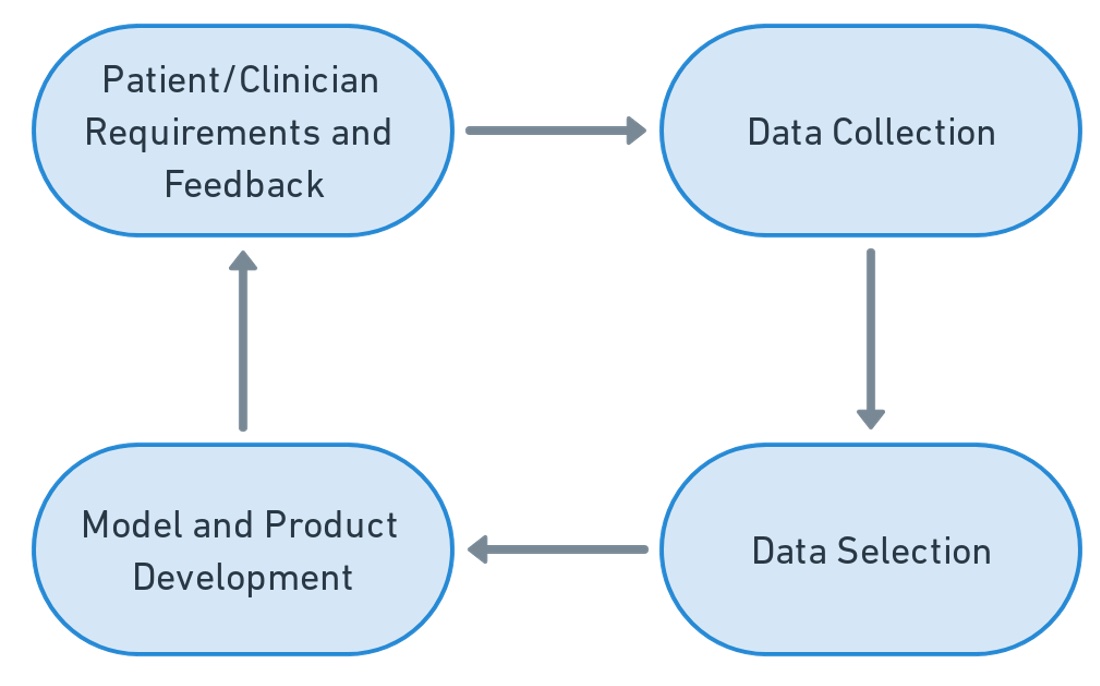
When building a system, it’s important to work backwards from the customer needs and to understand the existing standard of care. The main customers in healthcare are the clinicians and the patients. Since many AI-based diagnostic and treatment products are being integrated into clinician workflows, it’s important to include these customers in the design process. This can give the best chance of ensuring:
- Your product improves the existing standard of care and patient outcomes.
- It actually gets used!
What’s also incredibly important is that data scientists and engineers work closely with clinicians to pick the most representative and valuable data in the dataset. For example, if the intended use of your AI-enabled medical device is to detect early stage kidney disease, it’s important to work with clinicians to identify the most relevant samples that should be used for model training and evaluation. As new models are put into clinical care pathways, they should be continuously improved (as practical) based on the feedback of clinicians and patients.
2. Good Software Engineering and Security Practices Are Implemented
Developing AI-enabled software medical devices highlights some important engineering and security best practices. While not being a totally comprehensive list, below are some of the important key areas that you need to focus on:
- Security - follow security best practices, including in the areas of patient privacy, access restriction, periodic code and system audits and external security validation
- Source control - follow source code control best practices, setting up code review processes and having a continuous integration pipeline to ensure code changes don’t break model development or affect its performance
- Change management - develop a checklist and process that ensures model performance doesn’t degrade when data changes or new models are built. Have a process in place to rollback changes, if necessary (i.e. a two-way door).
- Testing - ensure your project has testing across all your code, data and systems, including:
- Unit tests for code modules
- System integration tests
- Canaries or monitors
- Model evaluation on test sets (e.g. gold test set)
- Data distribution checks
- Fairness in predictions test
- Data management - to ensure the data quality of your system, be sure to have:
- Audit trail of changes and accesses
- Version your data, to ensure system rollbacks and the reproduction of models (possibly use something like git and/or DVC)
- Ensure all data changes have a reviewer (similar to code source control)
3. Clinical Study Participants and Data Sets are Representative of the Intended Patient Population
To ensure your model predictions has the highest performance in a clinical setting, you need to ensure the samples in your dataset represents the population of patients. This is achieved through measurements of demographic information (e.g. race, gender, ethnicity, age), relevant clinical background (e.g. disease etiology, co-morbidities) and other factors (clinical setting, geography).
Fortunately tools like Microsoft Fairlearn have useful UI representations of any field you choose to check for performance disparity amongst one or more protected attributes. Data scientists should work closely with clinicians to identify protected attributes.
4. Training Data Sets are Independent of Test Sets
In machine learning, it’s important to evaluate models on a separate test data set to get a more realistic idea on how the model will perform in a real clinical setting. Model performance on training data is typically higher than on the test data.
5. Selected Reference Datasets Are Based Upon Best Available Methods
Following on principles 3 and 4, your reference or “gold” dataset should be used for model evaluation. This reference dataset should represent your target population. For example, if you are developing a diagnostic test for skin cancer, you need to ensure it captures the entire diversity of the patient population (e.g. race, gender, skin tone, geography, etc). Any production model changes should be evaluated on that gold dataset.
Depending on your use case and fairness constraints, you may consider having multiple gold test datasets and a separate test dataset that gets refreshed periodically based on clinical use in the field. This way, you can evaluate model changes more finely instead of in a single monolith gold test set.
6. Model Design Is Tailored to the Available Data and Reflects the Intended Use of the Device
A clear guiding factor in machine learning designs is to ensure your model is generalizable across many different factors. This is even more critical with biomedical models, as wrong predictions can increase the risks for patients.
As you’re designing your model development system or pipeline, you need to account for several data design issues that might affect how generalizable your model can be. These include including overfitting, security/privacy, performance degradation (e.g. in a clinical setting). Fortunately, many of these issues can be mitigated. For example, performance degradation can be detected early on by ensuring your model performances equally well in:
- Across various protected attributes (e.g. race, gender, age)
- Across different clinical settings, centers and geographies
7. Focus Is Placed on the Performance of the Human-AI Team
The performance of the model should not be measured in isolation of the model development and evaluation system. Rather, the performance of the model should be measured in real-world clinical settings with the model predictions in the clinical care pathway, where the “humans” (e.g. patients, technicians and clinicans) exist. Ultimately if the results of the model are not interpretable and actionable, then the model may not provide any performance benefit.
8. Testing Demonstrates Device Performance During Clinically Relevant Conditions
Principle 8 reinforces prior principles that have been previously covered. Following on principle 7, the testing of a AI-powered medical device should be done in a clinical setting instead of in isolation. Also as principle 3 states, the patient population in the test/evaluation sets should reflect the expected patient population in your clinical setting.
9. Users Are Provided Clear, Essential Information
If we’re following a user-centered design, this principle should really be the number one guiding principle. If the results of a model prediction are not clear and interpretable by the clinician or patient, then the model is likely not going to be clinically useful. As an example, if you have a diagnostic test, would it be more useful to have a prediction score with a bunch a conditional statistics or would a simple positive/negative result be better?
10. Deployed Models Are Monitored for Performance and Re-training Risks Are Managed
After a model is deployed to a product, it’s important to monitor the performance of the model in internal test sets as well as in representative clinical settings. These monitoring metrics should be specific. For example, if you have a diagnostic device, you might have a set of metrics and thresholds like:
- Sensitivity is at least 85% on the entire test set
- Specificity is at least 90% if the gender is female
- True positive rate is at least 80% across individual regions
These performance metrics are useful for detecting data drift. Data drift is the phenomenon when a model performance degrades over time due to one more factors.
To take a deeper dive into dataset drift and mitigations, I’d recommend reading this article from Evidently on handling dataset drift.
When models are retrained, it’s important to follow the same quality controls and risk mitigation strategies you used when developing the model. For example, you may have automated detection of overfitting and bias. When you’re retraining your model, it may also make sense to add or remove specific samples from your evaluation set. Given the nature of your device, it may make sense to subdivide your evaluation set into separate evaluation sets and keep track of performance metrics across all your evaluation sets.
Wrap-up
Overall, I thought this document provided some great high-level goals for a machine learning project in the medical device space. I think there’s some room for improvement in the list, especially in removing redudancy in the principles (e.g. between principles 3 and 5)
I’d like to see additional principles in the future that cover data valuation and clean labeling. For example, a principle might state something like “Have a process in place to ensure data set quality is maintained”